Cloning My Own Voice with VibeVoice and ComfyUI
Oct 18, 2025
Introduction
Recently, I experimented with using VibeVoice-Large (9B params) to generate a realistic English narration for my demo video — using my own voice as the reference.
The workflow ran entirely in ComfyUI, and I was surprised by how natural and accurate the cloned voice sounded — even reproducing subtle traits like my slight lisp :D.
My setup
Environment
- ComfyUI (latest build)
- ComfyUI Manager(3.35)
- VibeVoice Custom Node: Enemyx-net/VibeVoice-ComfyUI
Model
Tools
- 🎧 Recording: OBS
- 🎬 Editing: Adobe Premiere Pro
Audio Samples: Training Input vs Generated Output
(Duration: 1 min)
(Duration: ~3 min)
What I learned
Here are a few things I discovered while fine-tuning the workflow and experimenting with prompts and parameters.
1. Use lowercase for acronyms
The LLM doesn’t always pronounce uppercase abbreviations correctly.
For example, “ALT” might be read as “A — L — T”.
To fix this, write them in lowercase or phonetically (“alt”) if you expect a natural pronunciation.
2. Match your sample voice to the output context
If your target is a presentation, record yourself reading a presentation-style passage.
This helps the model pick up your pacing, tone, and emotional cadence, which leads to better results than using a mismatched sample (like a casual conversation or a exaggerated storytelling).
3. Keep voice_speed_factor at 1.0
It’s tempting to adjust this parameter, but even small changes can hurt output quality.
If you need faster or slower narration, adjust the playback speed later in Premiere Pro.
Let the model focus on clarity and natural rhythm.
4. Avoid fixed seeds
Surprisingly, using a fixed seed often introduced unwanted background noise at the start of the audio.
Switching to randomize produced cleaner, consistent results when using a real-voice reference clip.
5. Reference audio makes all the difference
Once I used my own 1-minute voice recording as a guide, the generated voice became almost indistinguishable —
not only capturing tone and timbre, but even small quirks like breath timing and tongue sounds.
It felt a bit uncanny, but in a good way.
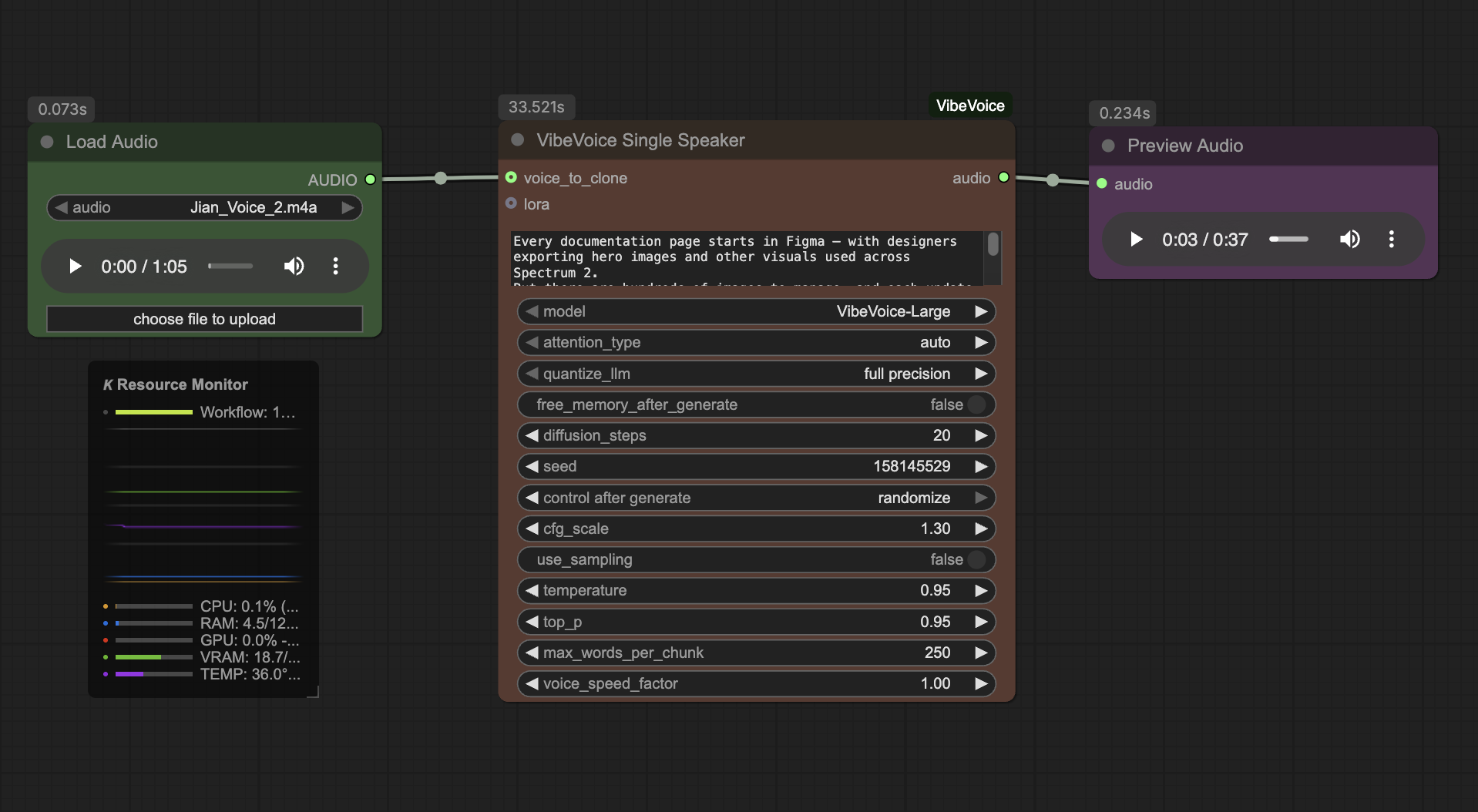
My minimal ComfyUI workflow
You can reproduce the setup with a simple node chain:
Final thoughts
Cloning your own voice for AI narration feels like magic — especially when the output sounds authentic enough for a live presentation. With ComfyUI and VibeVoice, the entire process was visual, controllable, and surprisingly intuitive.
That said, for VibeVoice to become truly production-ready, it still needs a variety of LoRA fine-tunes. Without them, the model struggles in more complex scenarios — for example, reading mathematical or physics formulas smoothly and accurately. Once domain-specific LoRAs are introduced, VibeVoice could evolve from a demo tool into a highly capable voice synthesis system for creative and technical presentations alike.